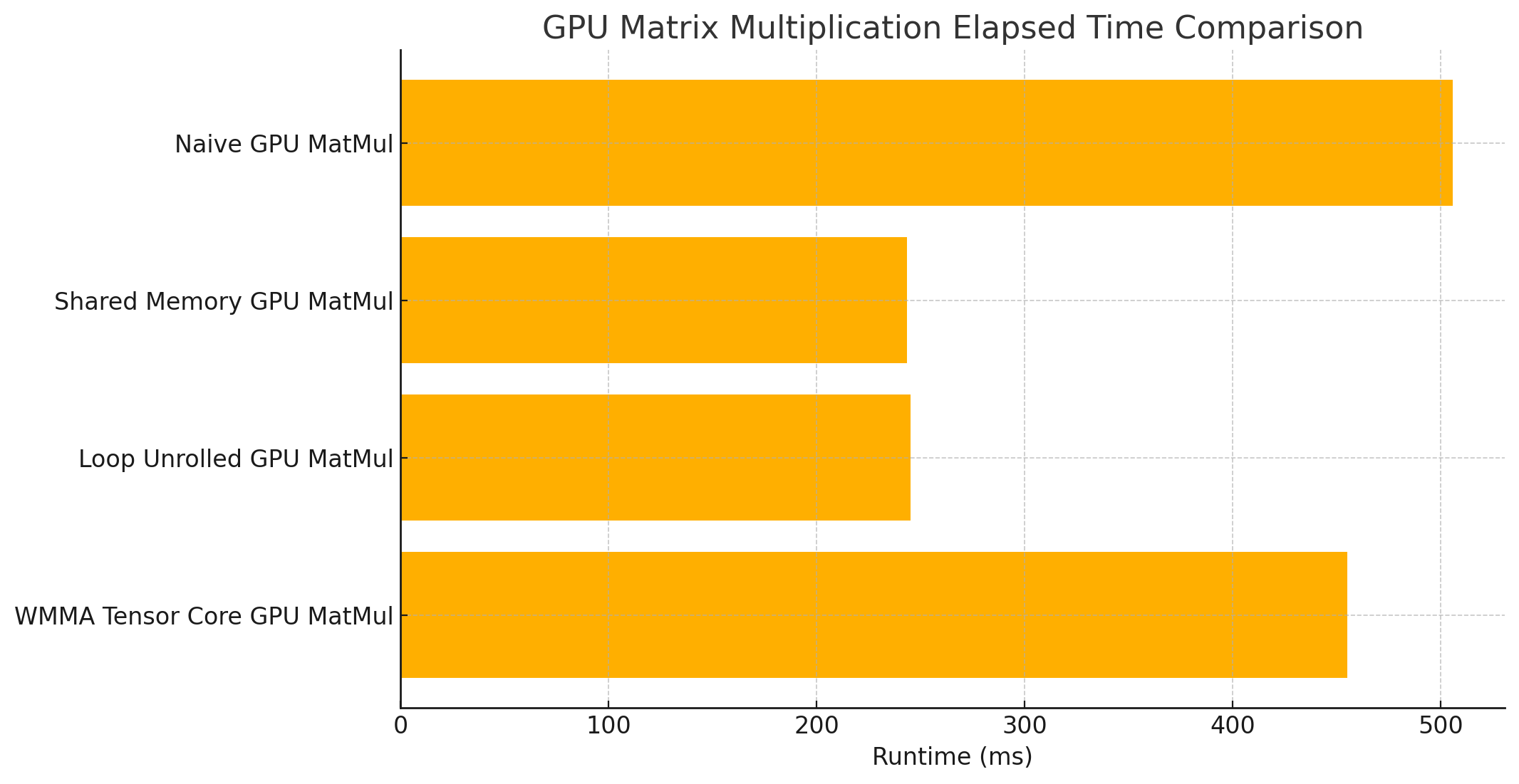
In this post, we evaluate the performance of different matrix multiplication techniques on an NVIDIA A100 GPU using an 8192x8192 matrix. With the powerful Tensor Cores available on the A100, we explore how various implementations, including WMMA (Warp Matrix Multiply and Accumulate) for Tensor Core acceleration, handle this computationally intensive task.
To better understand GPU optimization techniques, we implemented four matrix multiplication methods:
The naive implementation computes each element of the result matrix independently in each thread. This straightforward approach has no optimizations, so it requires multiple global memory accesses, resulting in longer runtime for large matrices.
// Naive GPU Matrix Multiplication
__global__ void matMulNaive(const int* A, const int* B, int* C, int n) {
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
if (row < n && col < n) {
int sum = 0;
for (int k = 0; k < n; k++) {
sum += A[row * n + k] * B[k * n + col];
}
C[row * n + col] = sum;
}
}
In this approach, shared memory is used to store small submatrices of A and B, reducing global memory accesses and improving performance. By using shared memory, we achieve faster data access within each block.
// Shared Memory GPU Matrix Multiplication
__global__ void matMulSharedMemory(const int* A, const int* B, int* C, int n) {
__shared__ int As[16][16];
__shared__ int Bs[16][16];
int row = blockIdx.y * 16 + threadIdx.y;
int col = blockIdx.x * 16 + threadIdx.x;
int sum = 0;
for (int i = 0; i < n / 16; i++) {
As[threadIdx.y][threadIdx.x] = A[row * n + i * 16 + threadIdx.x];
Bs[threadIdx.y][threadIdx.x] = B[(i * 16 + threadIdx.y) * n + col];
__syncthreads();
for (int k = 0; k < 16; k++) {
sum += As[threadIdx.y][k] * Bs[k][threadIdx.x];
}
__syncthreads();
}
C[row * n + col] = sum;
}
Loop unrolling further optimizes the shared memory implementation by reducing loop overhead, making this approach faster. This technique is particularly effective for smaller matrix sizes, where loop overhead is a significant factor.
// Loop Unrolled GPU Matrix Multiplication
__global__ void matMulLoopUnroll(const int* A, const int* B, int* C, int n) {
__shared__ int As[16][16];
__shared__ int Bs[16][16];
int row = blockIdx.y * 16 + threadIdx.y;
int col = blockIdx.x * 16 + threadIdx.x;
int sum = 0;
for (int i = 0; i < n / 16; i++) {
As[threadIdx.y][threadIdx.x] = A[row * n + i * 16 + threadIdx.x];
Bs[threadIdx.y][threadIdx.x] = B[(i * 16 + threadIdx.y) * n + col];
__syncthreads();
#pragma unroll
for (int k = 0; k < 16; k++) {
sum += As[threadIdx.y][k] * Bs[k][threadIdx.x];
}
__syncthreads();
}
C[row * n + col] = sum;
}
The WMMA (Warp Matrix Multiply and Accumulate) API allows us to use Tensor Cores on the A100 for matrix multiplication. Tensor Cores are specialized hardware units optimized for 16x16 matrix operations in mixed precision (FP16 inputs with FP32 accumulation). However, due to tile size constraints and the large matrix size (8192x8192), this approach may not always outperform shared memory-based techniques.
// Tensor Core Matrix Multiplication using WMMA
__global__ void matMulTensorCoreWMMA(const __half* A, const __half* B, float* C, int n) {
const int TILE_SIZE = 16;
int warpM = (blockIdx.y * blockDim.y + threadIdx.y) / TILE_SIZE;
int warpN = (blockIdx.x * blockDim.x + threadIdx.x) / TILE_SIZE;
fragment a_frag;
fragment b_frag;
fragment c_frag;
fill_fragment(c_frag, 0.0f);
for (int i = 0; i < n / TILE_SIZE; i++) {
load_matrix_sync(a_frag, A + warpM * TILE_SIZE * n + i * TILE_SIZE, n);
load_matrix_sync(b_frag, B + i * TILE_SIZE * n + warpN * TILE_SIZE, n);
mma_sync(c_frag, a_frag, b_frag, c_frag);
}
store_matrix_sync(C + warpM * TILE_SIZE * n + warpN * TILE_SIZE, c_frag, n, mem_row_major);
}
The following plot summarizes the performance results, illustrating the differences in elapsed times for each method.
The results indicate that shared memory and loop unrolling offer the best performance for large matrix sizes. While Tensor Cores are highly effective for small or batched matrix operations typical in deep learning, they were less beneficial here due to the overhead associated with managing small tiles for a large 8192x8192 matrix.