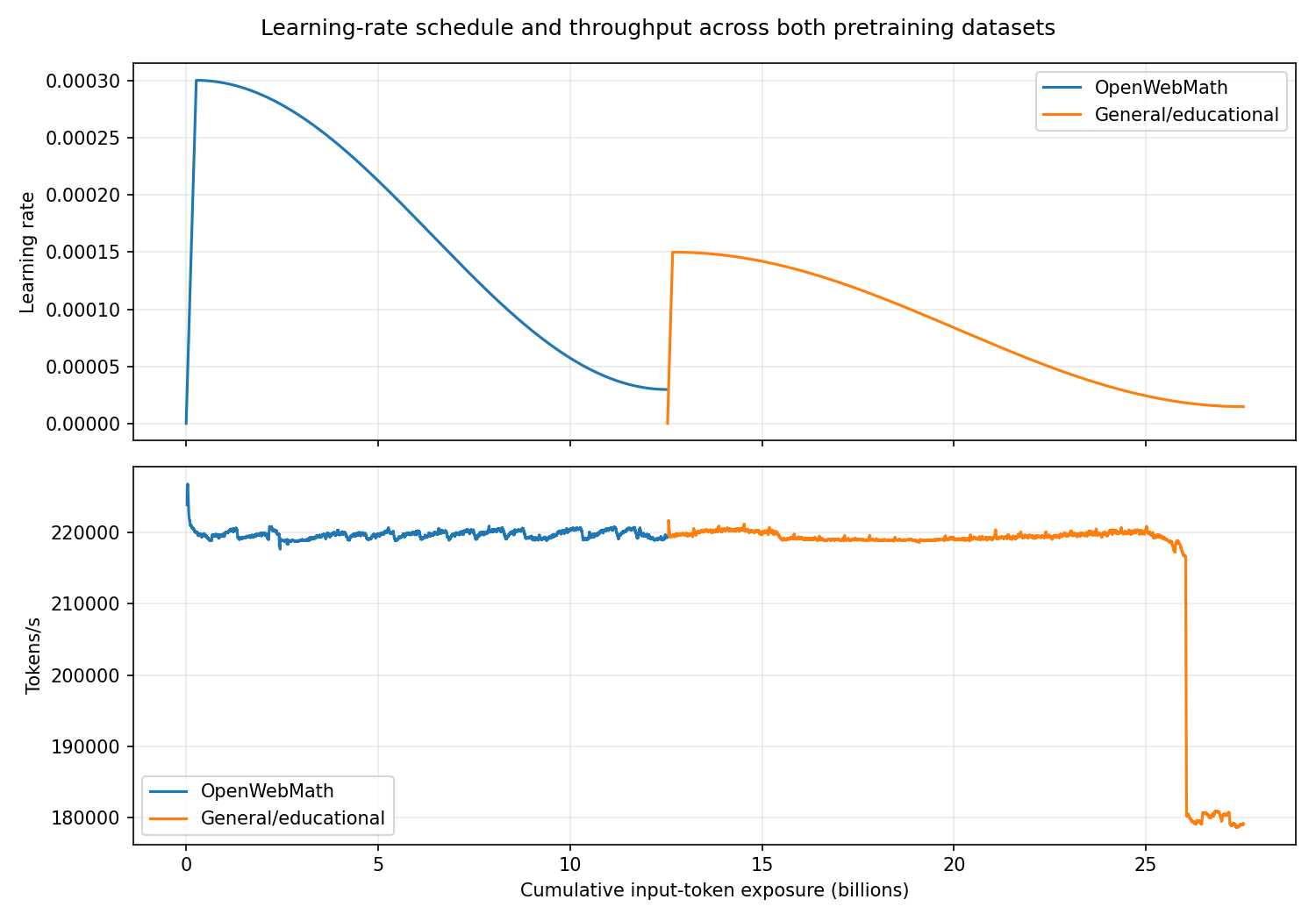
Figure 1. Learning-rate schedule and throughput across both pretraining datasets.
The equations in the Training chapter describe one optimizer update. Pretraining performs that update many thousands of times over billions of tokens. This is where a model acquires broad statistical representations of language, mathematical notation, explanations, and common reasoning patterns.
The central problem is efficient distributed execution: maintain high utilization, prevent input-pipeline stalls, partition examples across workers, synchronize gradients, and preserve numerical stability. Throughput, memory allocation, gradient norm, learning rate, and loss are operational diagnostics. Together they reveal whether input staging, communication, memory, or optimization behavior is limiting progress.
MyLLM uses 8 GPUs with an 8,192-token context, a global batch of 32 packed sequences, no gradient accumulation, and data-parallel training. Each optimizer update therefore processes
\[32\times8{,}192=262{,}144\text{ input tokens per step}.\]
The article treats Pretraining Data 1 and Pretraining Data 2 as the two pretraining datasets in the same training plan. The combined input-token exposure is
\[12.54\text{B}+15.00\text{B}=27.54\text{B input tokens}.\]
| Pretraining dataset | Input-token exposure | Steps | Wall time | Throughput | Purpose |
|---|---|---|---|---|---|
| Pretraining Data 1: OpenWebMath | 12,540,182,528 | 47,837 | about 15.9 hours | about 219k tokens/s | Mathematical web text, notation, derivations, definitions, and proof-like prose. |
| Pretraining Data 2: FineWeb-Edu + Cosmopedia auto_math_text | 15,000,061,824 | 57,221 | about 19.5 hours | about 214k tokens/s | General English, educational prose, textbook-like explanations, and student-facing language. |
| Total | 27,540,244,352 | 105,058 | about 35.4 hours | about 216k tokens/s | Math plus English tutor foundation. |
Pretraining Data 2 contains 13.25B unique complete tokens after 8,192-token packing: 12.00B from FineWeb-Edu and 1.25B from Cosmopedia auto_math_text. The optimizer schedule samples 15.00B input-token draws from Pretraining Data 2. For training compute and exposure, the relevant number is its 15.00B input-token schedule.
Figure 1. Learning-rate schedule and throughput across both pretraining datasets.
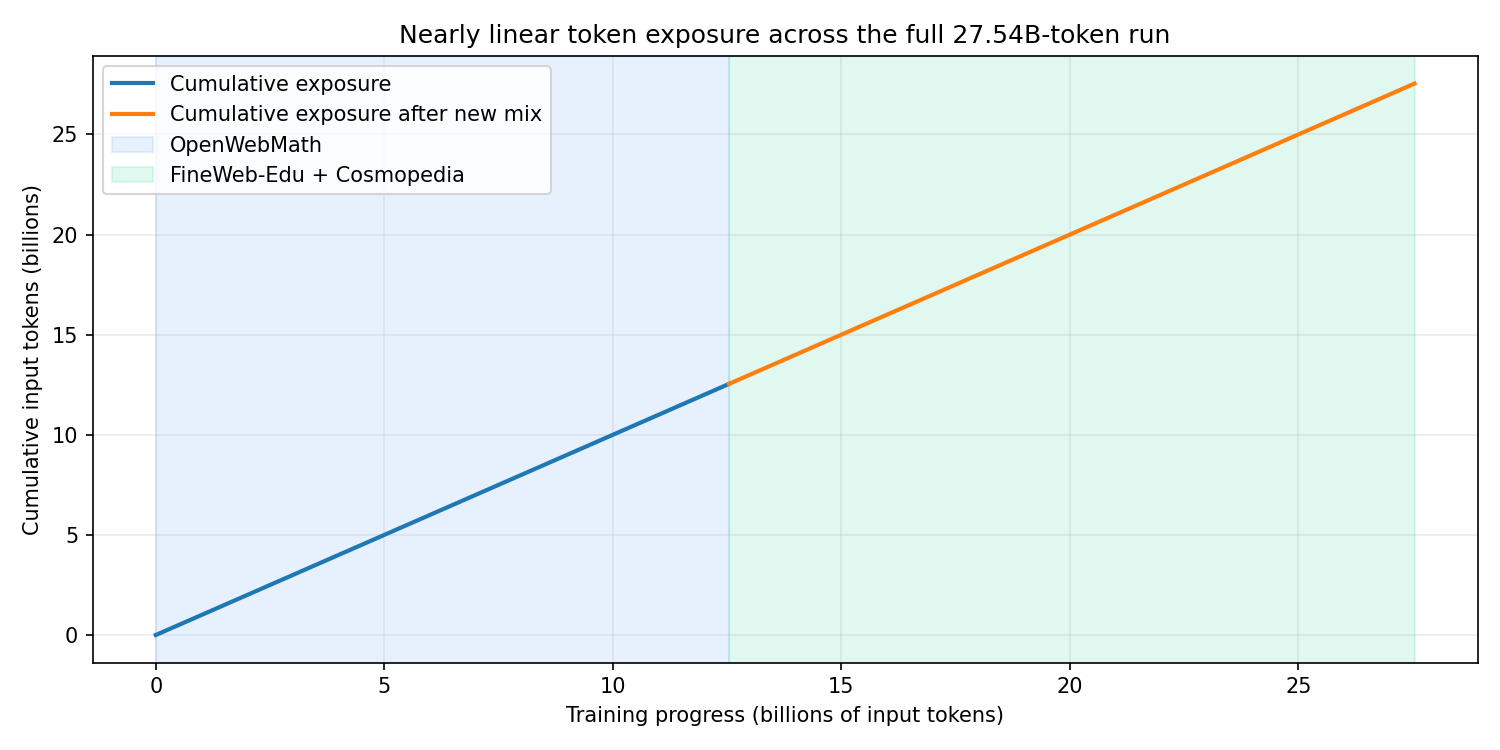
Figure 2. The full pretraining plan exposes MyLLM to 27.54B input tokens across Pretraining Data 1 and Pretraining Data 2.
Every optimizer step uses a full batch, so the nominal number of input-token draws is the step count multiplied by 262,144. For the full pretraining plan,
\[(47{,}837+57{,}221)\times262{,}144=27{,}540{,}244{,}352.\]
The average throughput across the full pretraining corpus is roughly
\[\frac{27.54\times10^9}{57{,}232+70{,}205}\approx216{,}100\text{ input tokens/s}.\]
Pretraining Data 1 has an initial loss near the random-uniform reference \(\ln(65{,}536)\approx11.09\) and falls to roughly 2.0–2.1. Pretraining Data 2 has a different data distribution, so its loss is reported as a separate curve: around 3.1 at the high end and near 2.6 by the end. The two curves should not be read as one continuous loss line; they are two pretraining datasets with different text distributions.
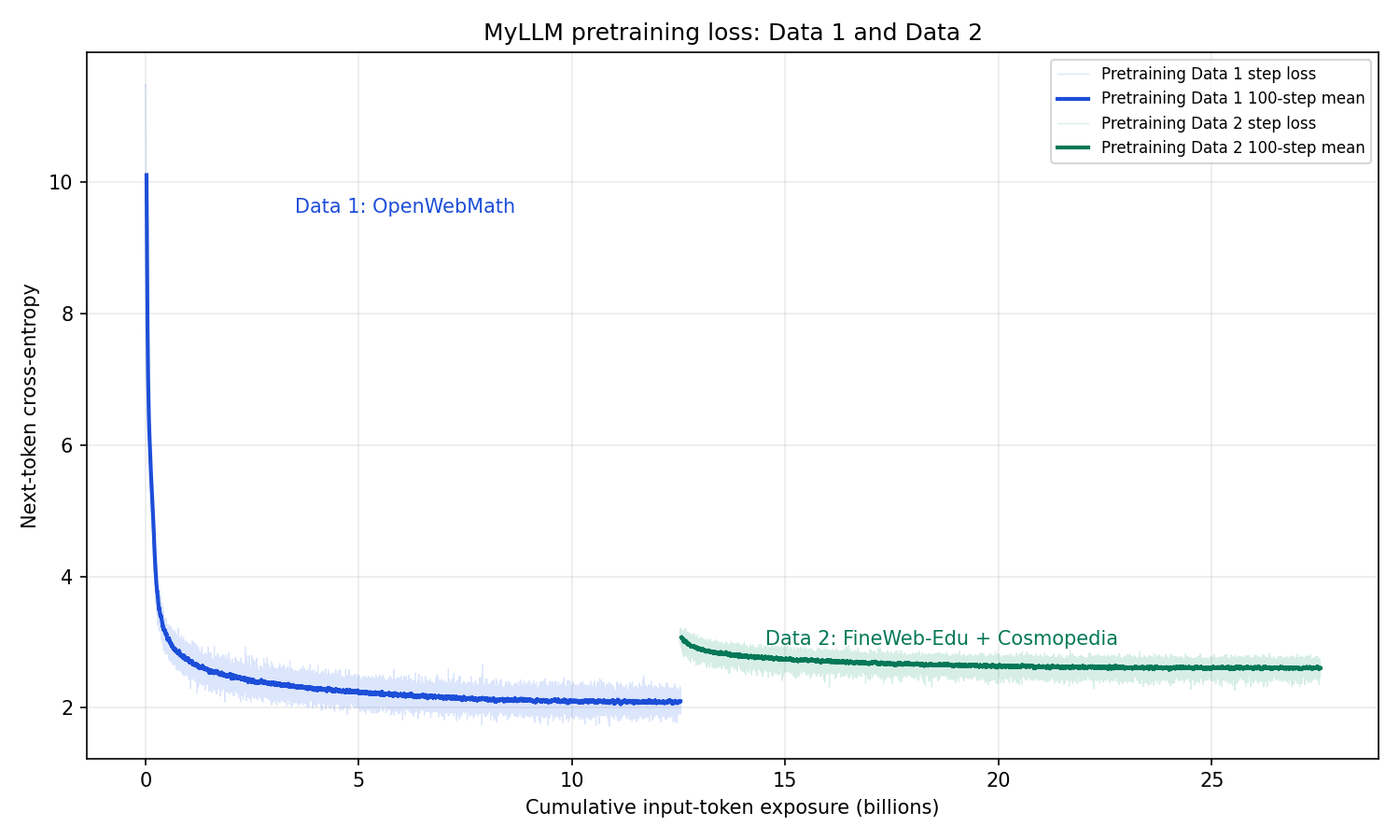
Figure 3. The loss curve reports Pretraining Data 1 and Pretraining Data 2 separately because their text distributions differ.